
Date: May 10th, 2021
Class: DS 340W
Instructor: Kaamran Raahemifar (Penn State University, College of Information Sciences and Technology)
Abstract
The insurrection that took place on January 6th, 2021 is an event that will go down in history as a catastrophic failure by the U.S. government. Heads eventually turned towards Parler, a social media site similar to Twitter as a breeding ground for the extremists to plan their attack on the capitol. Our team compared sentiment scores for Parler and Twitter posts. Posts were gathered from Twitter and Parler prior to January 6th. Separate posts were gathered to train a binary classifier that labels posts as political or non-political. The political posts were then processed to calculate their sentiment scores, and the averages were compared. The average negative sentiment scores for Twitter was higher than Parler for TextBlob, but was lower than Parler for NLTKVader. Average sentiment scores for positive and neutral were relatively similar between TextBlob and NLTKVader. Results are inconclusive, with NLTK Vader and TextBlob resulting in different results for average negative sentiment. In future work the classification testing and training sets should be much larger to better classify posts as political or non-political. More finely-tuned methods for sentiment analysis should be used to accurately determine whether negative and positive posts on average were different depending on sentiment analyzer.
Introduction
Social media since its introduction has had a big impact on politics since its inception. It is a great way for politicians and political campaigns to get a quantified idea of what their constituents are feeling and what they want. It is also a platform to influence people and movements on a massive scale. Politicians have a direct and personal line to their constituents via Twitter, that costs no money to communicate on. [9] There are even examples in recent history of foreign governments using social media in attempts to influence elections, such as Russia influencing the 2016 US elections. [10]
Twitter and parler are two social media microblogging websites that have some of the largest amount of political engagement online. Originally Twitter was the primary medium for politically motivated posts. However, due to censorship of multiple politically conservative posts and user profiles, the microblogging social media platform Parler emerged as an alternative. Parler’s purpose is very similar to twitter but its user base is largely made up of conservatives who flocked to the platform after key conservative figures were censored on twitter. [8]
We used a pre-collected data set of parler posts along with a set that we have collected from Twitter to compare the sentiments of politically motivated posts posted prior to January 6th. By doing this we can find out if there is a distinct difference between the political posts on Parler and the political posts on Twitter. We hypothesize that Parler has a lower sentiment score for posts in comparison to similar posts on Twitter. This is due to the general consensus by the media that Parler fosters extremist views, and thus tends to have a higher frequency of negative language in comparison to Twitter. To do this, we use data collection techniques, natural language processing tools, machine learning classification, and sentiment analysis using supervised machine learning.
Literature Review
There has not been much research done on Parler as a social media platform, as Parler as a service has not been popular until Twitter recently began moderating their platform for extremist content, most of which was related to Donald Trump and his followers. [1]
The field of sentiment analysis has been explored a lot by previous research papers. In a comparison between twitter and tumblr using empirical analysis two social media outlets were compared for sentiments to analyze their performance as data analytics tools. In order to acquire data you can use the APIs offered by the platform. The data acquired in this case was posts that mentioned certain events or used certain hashtags. They used stemming and tokenization to take words to their roots. They then used machine learning models to do sentiment analysis classification on multiple different models. [2]
Another expanse of sentiment analysis being was to create a model that analyzed stocks and covid-19. In this paper they used techniques to reduce the size of the input data such as tokenization, lemmatization, stemming, and stop word removal. They also used the log function to scale TF-IDF measures due to the large number and variety of words present in the posts related to their topics. The techniques mentioned will be useful to our analysis as we will be dealing with thousands of posts from both Twitter and Parler, and slimming the data down to something more manageable will allow for more clear insights into the sentiment of the posts as a whole. [2] In addition, while further researching the different types of sentiment analysis, we found a paper that goes into the different kinds of sentiment analysis including document level, sentence level, and aspect level. Document level sentiment analysis involves extracting text as documents and determining whether or not it expresses a positive or negative view. Sentence level sentiment analysis includes breaking down text into sentences and determining whether each sentence has a positive, negative, or neutral view. Aspect level sentiment analysis is also known as feature sentiment analysis which is a more fine-grained approach to sentiment analysis and it focuses on looking into the sentiment/opinion itself rather than a document or sentence. [6] We decided to take a document based approach to our sentiment analysis as we planned on making a binary classifier.
There have been many examples showing how difficult classifying a tweet as political can be. A study from the Netherlands in 2018 [7] showed techniques on how best to classify political data. Taking 3,000 tweets they manually labeled the classes so they could make supervised learning models, at the same time they made a rule based model and compared results. The supervised learning models were vastly superior to the rule based model that was created. The LogisticRegression, Support vector machine, random forest and classification regression trees performed the best out of all supervised models. We considered these and decided to use logistic regression for our classifier due to other papers[5] having strong results with the mode
Furthermore, in terms of classification of politics, there has been a variety of research done from political environments all around the world. One example we see is a series of 3-class sentiment classification on the run up of days leading to the February 2011 Irish general elections. The classes include “Positive Tweets’’, “Negative Tweets”, and “Neutral Tweets”. Though we planned on binary classification model, this paper gave us a good understanding on how complicated supervised machine learning can become when another class is added to the sentiment classification. [4] In a paper more related to American politics, sentiment analysis was used to classify users and determine homophily during the 2016 election. Homophily is the tendency for people to seek out or be attracted to those who are similar to themselves. In this context the study is looking at the tendency to interact with users that are similar to each other in political beliefs on twitter. [3]
Research Question
Our research question is “How do political posts from Parler and Twitter compare with regard to sentiment classes in distribution and on average?”. For this research paper we will define similar tweets as those that are classified as political, as our ultimate goal is to come to a conclusion on whether Parler has more negative sentiment on average compared to Twitter due to its less restrictive moderation and alleged conservative user base. This narrative was used by the media when explaining the reasoning as to why Parler was no longer supported by its platforms that it was hosted on, and verifying that in a quantifiable manner would be able to shed some light on whether that narrative was accurate.
We hypothesize that the Parler posts will on average be more negative than the Twitter posts, and that the distribution of Parler posts will be more negative than the Twitter posts on average. This is due to the aforementioned narrative that has been pushed by the media and the companies that dropped Parler after the controversy surrounding the insurrection at the capital.
Methodology
Data collection and manipulation
The data source that was used for Parler tweets was obtained from twitter user donk_enby. This data contained a total of 1.6 million Parler posts stored on AWS. These posts contained the raw HTML content of the Parler posts but did not have file extensions. Due to computational restrictions with regards to access and loading times, the selection of parler posts to around 50,000. To load the Parler posts into the environment the BeautifulSoup python package was used. Beautiful Soup is a python library built to pull content such as text out of HTML and XML tags. By using the function find_all the HTML content can be filtered to just certain HTML tags. In this case we filtered for div elements that were part of the class “card–body”, as the text from the Parler posts was stored there for every post. If the post did not contain text then it was not collected.
To gather tweets from January 5th on twitter an internet archive for twitter posts was used. The archive contained collections of compressed tweets within zipped folders and jsons files. Each json file contained multiple json objects, with each object representing one tweet. To get access to these tweets within the python environment, we used the json package to load the tweets iteratively into a list. Tweets were not included if the “lang” key of the json was not set equal to “en” for english. When the json file that was loaded in its post text header was empty we did not add the tweet to the list.
Post/tweet text was then cleaned, and then formatted for Bag of Words representation. Bag of Words is a word count of text, without consideration for order.This was done to create features for the classification model.
Political vs Non Political Classification
To have a corpus of posts and tweets that would be suitable to compare we had to filter out the ones without political information in them. Since we have collected 50,000 tweets from each platform, we must take these posts and classify which of them are political and which are not. To do this a supervised Binary Logistic regression model was used, as this type of model has performed well in previous research [7]. A supervised model requires a train and test set with labels to fit the data and measure performance. Acquiring this data was done using the twitter API to scrape posts with certain hashtags. Tweets were used for the classifier as labeled training data was needed and twitter allowed us to access easily classified data without having to manually label. With a little research we were able to find sets of hashtags that were extremely likely to include political discussion and other hashtags that are very unlikely to contain political tweets. The twitter API was set to only include tweets that were in English. Due to complications with acquiring academic research approval from twitter we were unable to gather tweets that were older than 30 days, and there was a limited number of tweets that were able to be collected. With the twitter API implemented 5000 tweets were collected and classified for the train/test data. This train set was not ideal for our classifier as the number of posts to be classified was much larger than the training set. However, due to not having access to the Twitter API in full we were unable to collect more. 2500 of these tweets were labeled as political and 2500 were nonpolitical.
Structure of classifier:
After the train/test data was loaded the data was cleaned, and then formatted for Bag of Words representation. The Bag of words vectorizer used had a max feature limit of 25000 with n-grams set to 1-3. TF-IDF vectorization was also tried but results were not affected in metric testing and performed worse on the real data. After vectorization, the corpus created was split into train and test subsets with an 80-20 split. The logistic regression was then run and tuned to find the optimal model.

Sentiment analysis:
Sentiment analysis was performed on the classified tweets that were considered political by the classifier. This was done by using the python packages NLTK Vader and TextBlob and their native sentiment score functions to calculate the sentiment scores. Sentiment scores fall between the range of [-1, 1], with classes of sentiment being defined by the user. In our case we want our bands to be equal, so we set the bandwidth to 0.66, as the total domain is of length 2. Therefore our bounds range at [-1, -1/3], [-1/3, 1/3], and [1/3, 1] for negative, neutral, and positive respectively.
Findings
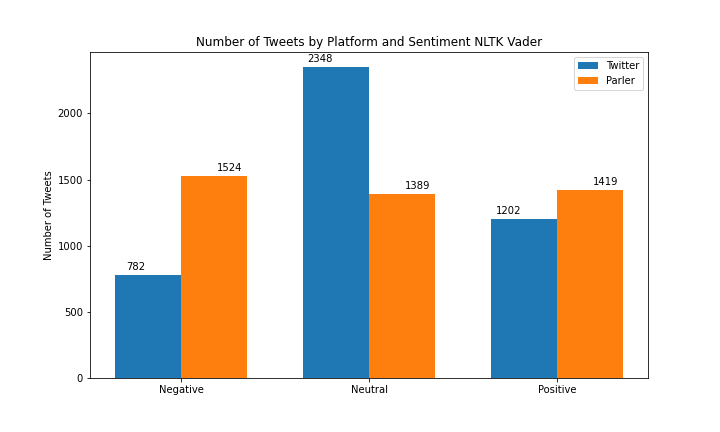
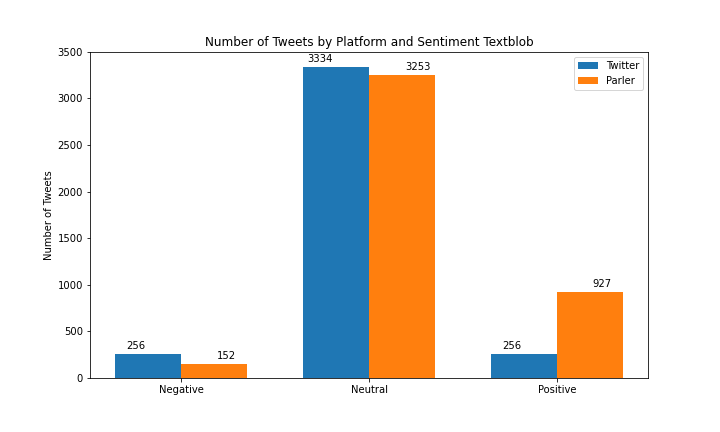
When comparing the NLTK Vader sentiment vs the TextBlob sentiment tools there was a major difference in results. Referring to figure (blah) the NLTK sentiment results were more evenly distributed across the three classes of sentiment than TextBlob with counts being 782 negative, 2348 neutral, and 1202 positive posts for Twitter, and 1524 negative, 1389 neutral, and 1419 positive for Parler. In the TextBlob sentiment results we observed that a large number of the posts were classified as neutral for both Twitter and Parler, with counts being 256 negative, 3334 neutral, and 256 positive for Twitter, and 152 negative, 3253 neutral, and 927 positive for Parler.
Parler and Twitter posts for NLTK sentiment Twitter had a higher number of neutral posts (2348 Twitter posts vs 1389 Parler posts), however Parler had a higher number of negative posts (1202 Twitter posts vs 1419 Parler posts). For TextBlob sentiment Parler posts contained more positive posts, (256 Twitter posts vs 927 Parler posts) and the number of posts between platforms were similar for neutral and negative. (3334 Twitter posts vs 2523 Parler posts and 256 Twitter posts vs 152 Parler posts respectively)

Comparing the overall average sentiment scores for Twitter and Parler from (figure) we observed that the NLTK sentiment scores for Parler were negative (0.019), and for Parler they were positive (0.057). However, both fall within the band for neutral, which was to be expected given that the distribution of post sentiment was even for NLTK Vader sentiment posts. For TextBlob both were positive, with Parler having a significantly higher average overall score than Twitter (0.136 vs 0.082). Both values also fall within the neutral band for sentiment scores.
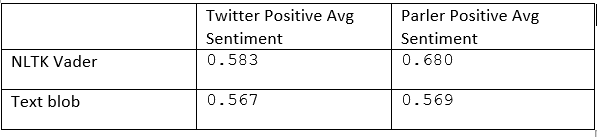
Comparing the average sentiment scores for positive sentiment between Twitter and Parler from (figure) we observe that for NLTK Vader Twitter is less positive on average than Parler (0.583 vs 0.680). The same occurs for TextBlob, but the difference is not nearly as significant. (0.567 vs 0.569) All values fall within the positive band for sentiment scores.
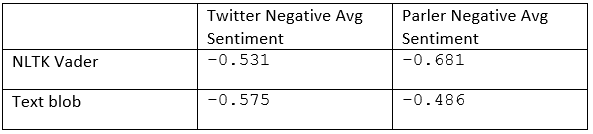
Comparing the average sentiment scores for negative sentiment between Twitter and Parler from (figure) we observed that Parler posts were more negative than Twitter posts for NLTK Vader. However, the reverse is true for TextBlob, with Twitter posts being more negative than Parler posts. All values fall within the negative band for sentiment scores.
Conclusion
With regards to our research question, “How do similar posts from Parler and Twitter compare with regard to sentiment in distribution?” we can not definitively draw a correlation between the different social media platforms and sentiment values. This is due to the fact that our classifier was not trained on a large enough data set to accurately classify tweets as political. Another issue was that our packages used to calculate sentiment gave wildly different results, so it is unclear which is more accurate in determining the sentiment values for our posts.
While our hypothesis that the distribution of posts would be more negative for Parler appears to hold true for the results from the NLTK Vader sentiment, the same cannot be said for TextBlob. Furthermore looking at average sentiment values for negative posts
Discussion
There are many aspects of this paper that are not optimal in execution but were used out of necessity. The set of twitter posts used was not focused enough for our liking and had a large amount of non relevant tweets due to having to use the InternetArchive. The political classifier used had training data that was too small for the dataset it was predicting and did not have labeled parler posts to learn off of. The packages that were used for sentiment analysis clearly showed a high variance and were not properly optimized for our classification needs. However we did end up a handful of interesting results and good insight on how future work could be effective.
Future Work
In terms of future work, there are a variety of alternative ideas that we have both discussed and further researched. A significant one would be utilizing the Twitter archive api to collect tweets instead of a third-party archive such as the internet archive. This requires twitter developer account access and academic research verification on that account. This would give a more streamlined approach to collect Twitter posts as a focused post scraping can be achieved using the built in archive API. As a result, this would improve the quality of our dataset as it allows us to gather more posts from january 5th that are directly related to our research question. One should also strongly consider making their own sentiment analysis model. The ability to train the sentiment model on the gathered dataset would add a level of accuracy that the packages we imported can not compete with. This would allow for more insight to come out of the sentiment analysis and ultimately the research. Analysis of a larger scope of data could also be done. By using data from dates before and after january 5th, insight could be found into the leadup and aftermath of the capital breach on social media.
Novelty
This paper is novel in the aspect of working with data from Parler. As of 4/20/2021 there are no published papers using Parler for any kind of text analysis. Many of the techniques, concepts, and models have been used before in classification and sentiment analysis papers.
[1] Kumar, Akshi, and Arunima Jaiswal. “Empirical study of twitter and tumblr for sentiment analysis using soft computing techniques.” Proceedings of the world congress on engineering and computer science. Vol. 1. 2017.
[2] Jain, Yuvraj, and Vineet Tirth. “Sentiment Analysis of Tweets and Texts Using Python on Stocks and COVID-19.” International Journal of Computational Intelligence Research 16.2 (2020): 87-104.
[3] Caetano, Josemar A., et al. “Using sentiment analysis to define twitter political users’ classes and their homophily during the 2016 American presidential election.” Journal of internet services and applications 9.1 (2018): 1-15.
[4] Bakliwal, Akshat, et al. “Sentiment analysis of political tweets: Towards an accurate classifier.” Association for Computational Linguistics, 2013.
[5] Brunna de Sousa Pereira Amorim, André Luiz Firmino Alves, Maxwell Guimarães de Oliveira, and Cláudio de Souza Baptista. 2018. Using Supervised Classification to Detect Political Tweets with Political Content. In Proceedings of the 24th Brazillian Symposium on Multimedia and the Web (WebMedia’18). ACM, New York, NY, USA, Article 4, 8 pages. https: //doi.org/10.1145/3243082.3243113
[6] Jagdale R.S., Shirsat V.S., Deshmukh S.N. (2019) Sentiment Analysis on Product Reviews Using Machine Learning Techniques. In: Mallick P., Balas V., Bhoi A., Zobaa A. (eds) Cognitive Informatics and Soft Computing. Advances in Intelligent Systems and Computing, vol 768. Springer, Singapore.
[7] Araújo, E. and Ebbelaar, D. Detecting Dutch Political Tweets: A Classifier based on Voting System using Supervised Learning. DOI: 10.5220/0006592004620469 In Proceedings of the 10th International Conference on Agents and Artificial Intelligence (ICAART 2018) - Volume 2, pages 462-469 ISBN: 978-989-758-275-2
[8] Needleman, Sarah. “What Is Parler? Conservative Social-Media App Denied Apple’s App Store Access.” WSJ, 11 Mar. 2021,
[9] “How Social Media Is Shaping Political Campaigns.” Knowledge@Wharton, 17 Aug. 2020, knowledge.wharton.upenn.edu/article/how-social-media-is-shaping-political-campaigns.Henschke, Adam, et al.
[10] “Countering Foreign Interference: Election Integrity Lessons for Liberal Democracies.” Journal of Cyber Policy, vol. 5, no. 2, 2020, pp. 180–98. Crossref, doi:10.1080/23738871.2020.1797136.