
Date: May 5th, 2021
Class: SODA 308
Instructor: Burt Monroe, (Penn State University, College of Information Sciences and Technology)
Introduction
The Academy Awards, or the Oscars, is the most influential award show in the movie industry where best films of the year are awarded since 1929 (Zauzmer, 2020). Every year, cinephiles and general movie fans all over the world tune in to witness the awards being given out. Predicting the Oscars has also become very popular among movie fans. On the largest prediction site, Gold Derby, there are more than 10,000 users trying to predict the final winners every year. This year, due to the COVID-19 pandemic, the film industry is facing unprecedented challenges.
Firstly, there are less blockbuster movies coming out this year due to boxoffice concerns. Looking at this year’s Best Picture nominees, the only “normal” Oscar movies are Mank and The Trial of the Chicago 7. The other six nominees are low-budget independent movies, which are mostly likely not gonna be nominated in a normal year.
Second, the awards season had been prolonged, with the Oscars awards ceremony being postponed to be held on April 25th.
Most importantly, because of the pandemic, all awards season screening had been held online instead of in-person. Many Oscar voters have complained openly because they cannot enjoy the screening in theaters and they cannot converse with other members and get to know their opinions. All these changes have made this year’s Oscar race more unpredictable than ever.
To predict the winners, there are a variety of factors to take into consideration, which we will briefly introduce in the background section. Considering that social media can influence public and private opinions about these nominated movies, in this project, we investigated whether we can use twitter sentiment scores to predict the winners. Since the most talked-about Oscar categories on twitter are Best Picture, Best Actor, Best Actress, Best Supporting Actor and Best Supporting Actress, we will limit our prediction scope to these five main categories.
Background
There have been some attempts to apply quantitative methods for Oscar prediction in the past few years with varying degrees of success (Ables, 2019; Stutzenstein, 2021; Zauzmer, B., 2020). Zauzmer (2019) even published a book about using data science to predict oscar winners.
There have been some attempts to apply quantitative methods for Oscar prediction in the past few years with varying degrees of success (Ables, 2019; Stutzenstein, 2021; Zauzmer, B., 2020). Ables (2019) studied the determinants of Oscar success using a multilinear regression model using variables such as genre, content, precursor results, MPAA ratings, etc. and obtained a 66% accuracy using the model to predict Best Picture winners in the past 40 years. The success rate is acceptable with room for improvement.
Ben Zauzmer has been using different prediction models to predict Oscar results for years and has written a book detailing the methods he attempted (Zauzmer 2019). He recently announced his prediction of this year’s Oscar nominations in the Best Picture category and obtained an accuracy of 5/8 (Zauzmer 2021). In addition, Zauzmer studied various variables affecting the final results such as release date. He concluded that later release dates can increase nomination probabilities and add revenue for Oscar nominees (Zauzmer 2020).
However, the movie industry faced unmatched challenges due to the COVID-19 pandemic in the past year. The Oscars have been postponed and even the eligibility rules have been modified to allow on-demand streaming movies to compete. The unprecedented circumstances make prediction purely based on historical data less useful for this year.
Alternatively, other researchers have been using social media data to predict Oscar outcomes. Malyack et al. (2020) analyzed the correlation of twitter activities and Oscar winners from 2015 to 2019 through retweets, mentions, hashtags, and favorites. They applied logistic regression and time series decomposition to determine whether which factor was related to Oscar winner forecasting. Interestingly, their only significant finding was that best picture winners had significantly fewer total retweets than non-winning nominees. Stutzenstein (2021) compared prediction results using box office data and Twitter data, and concluded that “Twitter data are not significant and do not add value for the prediction of Academy Award winners”.
However, this year, the box office data has minimal impact as most theaters are still closed in the US. And given the influence that social media can play in swaying public and private opinion on movies, we believe that we can use Twitter post sentiment on related hashtags to movies and predict Oscar winners based on sentiment score amongst other features.
Research Question
The research question is:
“Can sentiment scores of Twitter posts be used to predict the Oscars results?”
As sentiment is not the only possible indicator of performance at the Oscars, movie ratings were also used as a predictor for the final model. Our hypothesis is that sentiment scores will be a significant feature in predicting Oscar results.
Data
The data was collected from the Twitter API using Tweepy, a python package used to access the Twitter API. The search parameters that were used to search for the tweets were “#oscars” and “#person/movie name”. As Twitter posts related to the Oscars start to increase in frequency as time moves closer to the Oscars, we gathered 100 posts from each day of the week (April 16th - April 23rd) prior to the Oscars, for a total of 800 tweets per person/movie. All the posts were added to a pandas dataframe for easy accessibility. Each row contains the name of the person/actor, the text of the tweet, the favorite and retweet counts of the post, and the date the post was posted.
Data was also collected from IMDB and Rotten tomatoes to obtain community and critic ratings for movies. This was done in order to calculate the total probability of a picture/person winning the Oscars. From IMDB the community rating was collected for the movie itself or the movie that the person performed in. From Rotten Tomatoes the critic score and audience score for the movie itself or the movie that the person performed in were collected.
Methods
After the tweets were collected, they needed to be cleaned for sentiment analysis. The entire string of the text is set to lowercase, and any @ signs, links, numbers, and plus signs are replaced with a space. Stopwords including additional words related to retweets such as rt, rts, and retweet are removed from the text. Stopwords are words in the english language that are most commonly used such as you, it, be, etc. The words in the post were also stemmed using NLTK’s PorterStemmer. Stemming is taking words to their root form, so that different variations of a word are not counted as different words, and are instead counted as the same word.
After this process the Natural Language Toolkit (NLTK) package from python was used to calculate sentiment scores. Specifically the SentimentIntensityAnalyzer from the NLTK Vader package This sentiment scores returned are the negative, neutral, positive, and compound sentiment scores for the text. As in this project we are only concerned with the overall sentiment, we used the compound sentiment score metric for each post. The dataframes were then split based on the name of the person/picture, and then the average sentiment compound score was calculated from the new dataframes. This is the value that was used as the sentiment score value for the probability calculation of a person/picture winning the Oscars.
In order to calculate the probability of a person winning the Oscars, we needed to scale the entire score to 1. As we have 4 features, sentiment score, IMDB score, Rotten Tomatoes audience score, and Rotten tomatoes critic score, for this project each score was scaled to between 0 and 0.25. Once all the features were scaled, they were added up together to calculate the probability of a person/picture winning the Oscars.
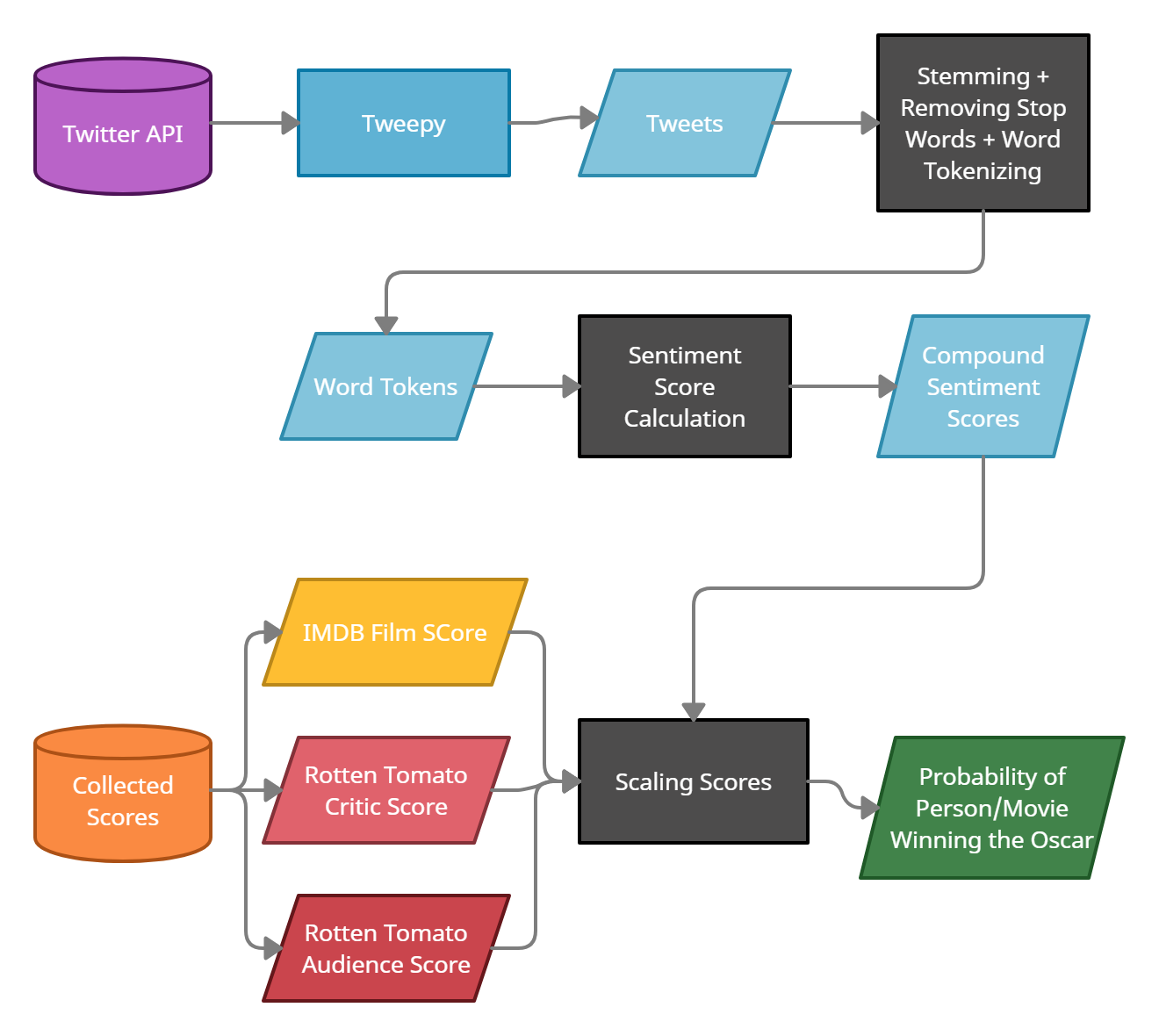
This entire methodology was performed on the five categories that we were predicting (Best Actor, Actress, Supporting Actor, Supporting Actress, Picture). The results were then compiled into a CSV in tidy data format to visualize in ggplot in R. This included the name, category, imdb score, rotten tomato audience score, rotten tomato critic score, sentiment score, and probability of oscar win.
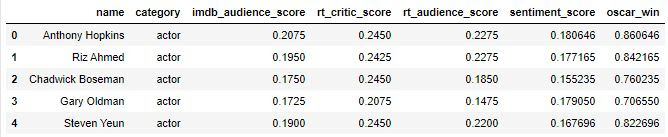
Results
After all the pre-processing steps,and using all the methods we talked about above, we finally can get all the results we want. For each category, we get the results of sentiment score and the oscar winning probability.
We put all the results in the excel and then import the excel to R to make it visualize as bar plots.
ggplot(actor.data, aes(x=name, y=oscar_win)) +
geom_bar(stat="identity", color = "purple", fill = "pink", show.values = TRUE) +
geom_text(aes(label=oscar_win), vjust = -0.3, size = 3.5) +
geom_smooth(color = "pink", se = FALSE, method = "lm") +
coord_cartesian(ylim = c(0.6, 1)) +
labs( title = "Best Actor Winning Probability.",
x = "Name",
y = "Probability of Oscar Win",
caption = "Source: Tweets Data"
)
To get the bar plot from which we can visually determine which one is predicted to win.
For the sentiment score predictions
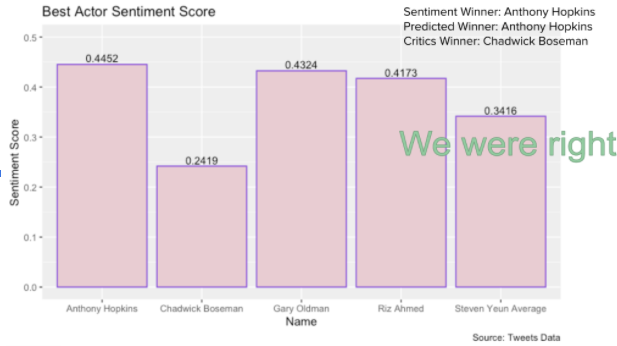
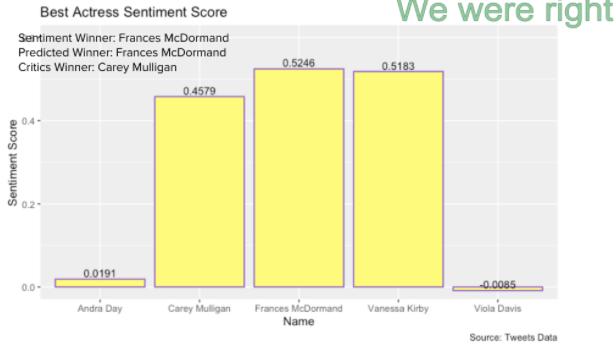
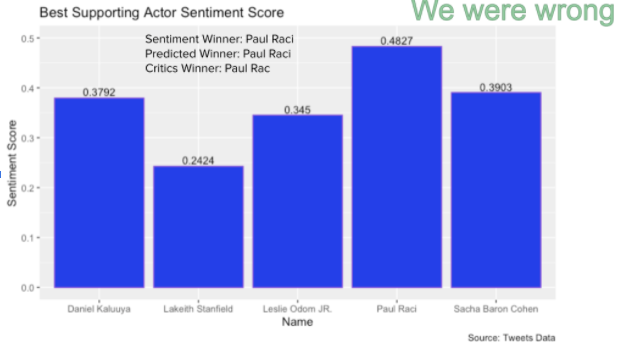
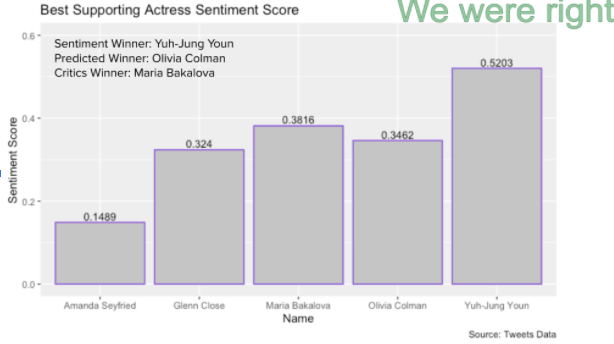
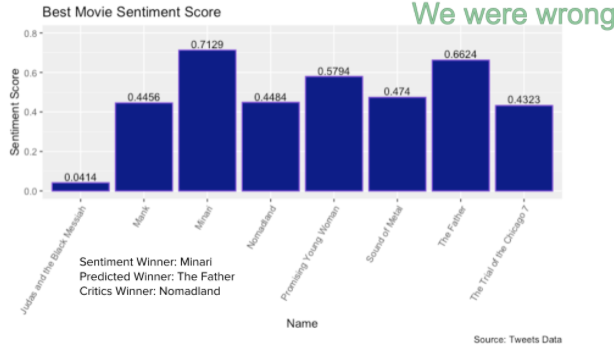
Sentiment Score Predictions Results Summary
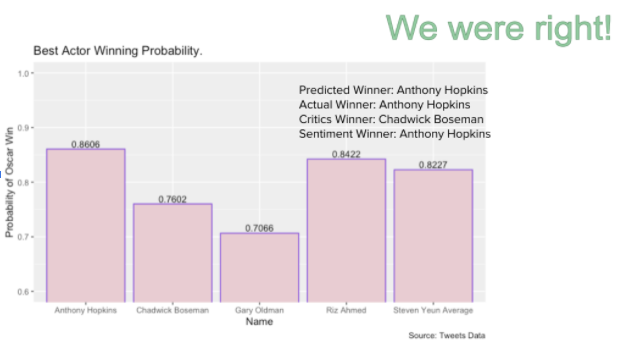
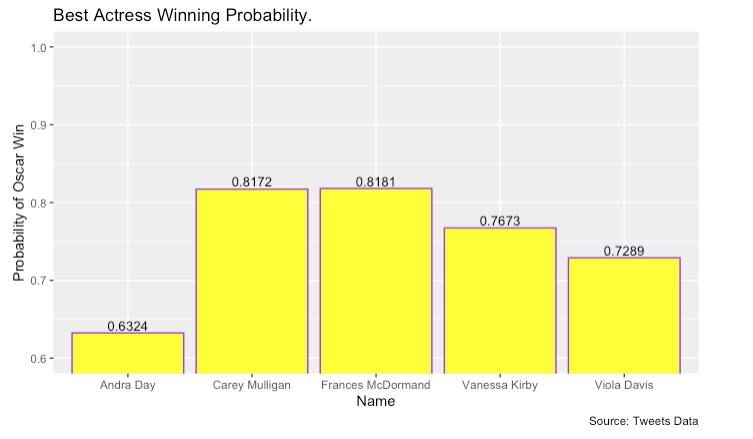
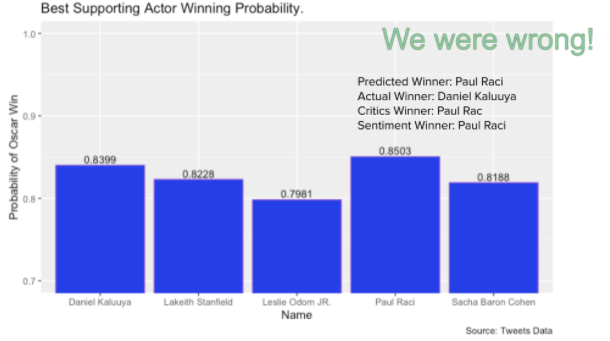
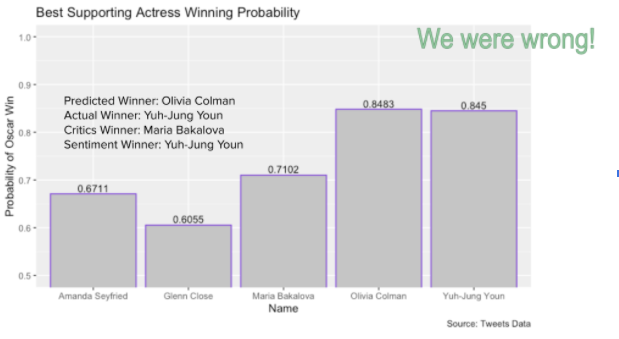
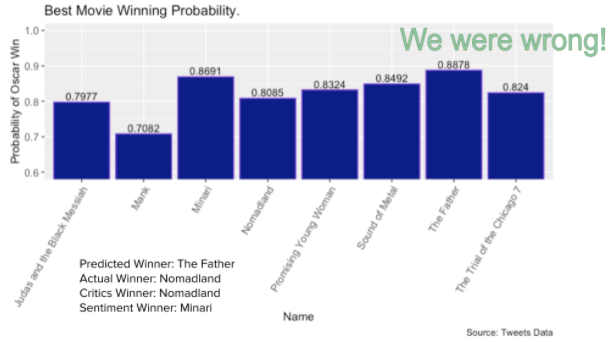
For the sentiment score winner predictions, we got the predictions right for best actor, best actress and best supporting actress, and got the predictions wrong for best supporting actor and the best movie, which is ⅗ for the total prediction accuracy.
For the Oscar Winner probability predictions
Oscar Winner Probability Prediction Results Summary
For the oscar winner probability predictions, we got predictions right for best actor and best actress, and got the predictions wrong for best supporting actor, best supporting actress and best movie, which is 2 out of 5 or 40% accuracy on our predictions.
Another thing to note with our results is that if our predictions were wrong for our probability model then the winner was always at least second place in our predictions, indicating that our model is at least performing well relative to expectations. Further analysis could help us understand how close we were from a probability perspective.
Discussion
From our results, it is undetermined as to whether sentiment is a good predictor for predicting Oscar results. The sentiment scores alone predicted three out of the five categories. Our final probability model only got two out of five categories correct, and this could be interpreted as meaning that the IDMB scores and Rotten Tomato scores were not good predictors.
In the presentation it was addressed that some of our results were interesting, such as Chadwick Boseman having low sentiment scores, Paul Raci and Minari having very high sentiment scores. The Chadwick Boseman posts were posted in the context of his death, and therefore had words associated with death, which would be more negative. That would explain why his sentiment scores were low, despite the fact that he was a favorite to win the Oscar. Minari had a very high sentiment score because the asian community was very passionate about the movie, and were most likely the ones who were talking the most about it online and therefore raised the sentiment scores that way. It is unclear why Paul Raci had such a high sentiment score, but more research could be done to see why this was the case.
An interesting observation was that our results were very close for our probability model when looking at the critics choices results. This could be because critics are very active on twitter when voicing their opinions on movies, and people are influenced by critics. As such twitter post sentiment scores could be a fantastic predictor specifically for critic choice awards since twitter is so easily affected by influencers and the like.
Sentiment score was also in a unique position this year at the Oscars to be a great predictor for the results. Usually the Oscar committee members watch the movies together in a theater, and they were able to discuss their opinions on movies in person. However this year due to the pandemic they had to watch the movies at home, isolated from other people. They had to go to social media platforms such as twitter to know what other people think of the movies that they were evaluating. This could explain why average twitter post sentiment scores can be a decent feature to use for Oscars results predictions specifically for this year.
Limitations
Our prediction of the Oscar winner is about half correct. There are several limitations that prevent us from predicting it more accurately. First, it is hard to collect more tweets due to the request cap and number of tweet cap per request. And we can only collect the tweets of the past month, but cannot go back further when we connect the tweets.
The second limitation is review bombing. We used ratings on IMDB and Rotten Tomatoes as one feature of predicting our final results, but sometimes the ratings on these public review sites are skewed by users who want to change the public perception of a movie, which is something we cannot count.
The third one is our score weighting. The way we weighed the final grade is 25% of each public review site’s ratings plus 25% Twitter sentiment scores, which is pretty arbitrary. We could do it better by doing more research about public opinions and private opinions on Oscars, but it would take a lot more work.
The last one is that we only predicted five categories of Oscar Award, if we could predict more instead of five, we could have a better understanding about how sentiment scores perform in the process of prediction, and then we could determine the weight of the sentiment rating in our prediction.
Future Work
For the future work, there are several things that can make our predictions more clear and precise. As we mentioned in limitations, we can start earlier before the next prediction so that we could have more data from Twitter, which can be used as the sentiment score in our prediction. The other thing is that we can do some further research, like collect public and private opinions, for weights for the final probability metric.
Conclusion
In conclusion we were attempting to predict the Oscar results for Best Picture, Best Actor, Best Actress, Best Supporting Actor, and Best Supporting Actress. We hypothesized that using sentiment scores of twitter posts would be a significant feature in predicting the winners. While our results remained inconclusive as to whether sentiment scores of twitter posts are a significant feature, we can say at the very least that they were helpful and painted a picture of how the public felt about the Oscar candidates.
Our results themselves were very close to accurate, with the winner always being second place or above in our final predictions. In future work in order to determine whether sentiment was a determining feature we would predict many more categories to get a better idea of how accurate our model is, since five categories is too small.
References
Ables, P.(2019) Predicting the “Best Picture” Oscar Award Winner. GRJ, 1. Malyack, Colette Therese, Krystal M. Hunter, and Starr Roxanne Hiltz. “Twitter and the Prediction of Oscar Winners.” (2020).
Stutzenstein, K. (2021). Do data from twitter improve predictions of Academy Award winners? (Doctoral dissertation, Universität Linz).
Zauzmer, Ben. Oscarmetrics: The Math Behind The Biggest Night In Hollywood. 2019. Zauzmer, Ben. (2020). Oscar Seasons: The Intersection of Data and the Academy Awards. 2.1, 2(1).